

As a freshman in college majoring in computer science, my extracurricular development experience prior to my Shoreline internship was limited to personal projects and apps I had helped build as a team in various student organizations. So coming into my summer internship at Shoreline, I was excited to have my first opportunity to work in the industry at a startup to help develop a real-world product. During my ten weeks at Shoreline, I learned a lot, gained valuable experience, and met some great people.
My Work at Shoreline
For context, Shoreline provides real-time automation and control for cloud operations. The Shoreline Agent is a small process running in the background of all monitored hosts, aggregating metrics data and allowing customers to query their fleet Resources in real-time.
Performance Improvements
Therefore, my first couple of assignments at Shoreline involved performance improvements in the execution time of large-scale distributed metric queries and Linux commands. The core issue with the current implementation was that the backend took about 6-7 seconds to respond after a customer entered their query into the CLI. The diagram below shows the general path of how a metric query executes.
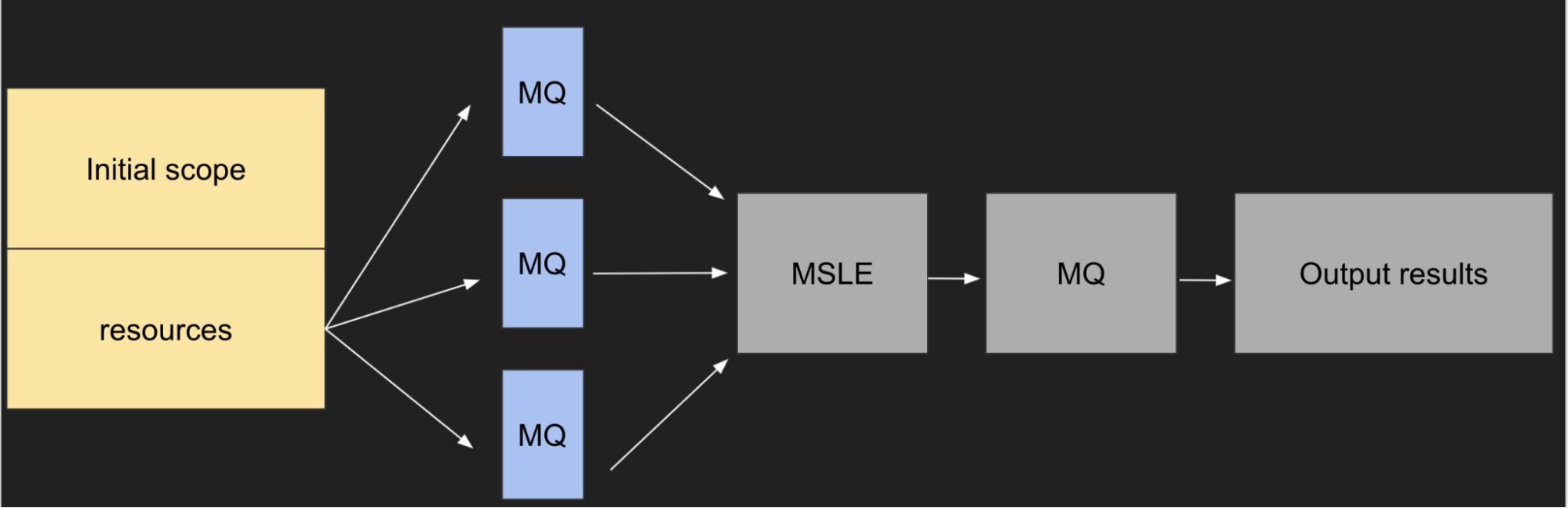
Shoreline metric query execution steps
- The Agents receive and execute the customer's metric query (MQ).
- The merged result (MSLE) is decoded and forwarded to any additional metric queries, which created significant bottlenecks as fleet size increased.
- The process repeats until all queries resolve and the customer sees the final output.
The initial scope with details about all the resources were being sent to all the Agents and they were sending it back to the Backend. Pruning the scope so that it propagated only the required data for each step improved the performance significantly. After scalability testing on a 200-Agent environment, the metric queries that once took 6-7 seconds were down to 1-2 seconds.
Shoreline Azure Agent
Beyond performance improvements, my main project for the summer was starting the development of the Shoreline Azure Agent. Before this project, the Shoreline Agent was only available to customers who had their machines running on AWS. When I look back on my internship at Shoreline, it was a great company to work at because I did significant work, as opposed to low-level typical "intern" tasks that no one else wanted to do. In addition, as a rising startup company about to emerge from stealth mode, the magnitude of this project was pretty significant - it would open up a new set of customers because Microsoft Azure is the second most popular cloud provider.
Azure is slightly different from AWS: the equivalent of an AWS EC2 instance is an Azure VM. For example, Azure uses a resource hierarchy account, subscription, resource group, and resource, while AWS uses account, region, and resource. There are also many differences in the instance metadata tags (tags tied to a VM instance such as name, location, etc.) between Azure VMs and EC2 instances. These differences and more had to be accounted for and kept in mind when modifying the Shoreline agent to support Azure VMs.
Before a custoer can monitor their fleet, their hosts must be "discovered" by the Shoreline Agent running on the machine and then "registered" internally in Shoreline's database. So naturally, this was the first step of developing the Azure Agent. After discovery, the first thing I implemented was making sure the Agent was on an Azure VM instead of a different cloud provider. I did this by using the attested metadata URL to receive a signed certificate that contained VM-related details.
Then, I added the tags collection implementation by calling the "instance metadata service," which returns all of the metadata tags for the VM. Instance metadata tags worked slightly differently between AWS and Azure: in AWS, each tag is retrieved from a request to a specific URL, and tags are retrieved that way individually. In Azure, one batch call retrieves all of the tags at once in a JSON response, which can then be parsed and handled internally.
There are also differences in provider tags: for example, in AWS, region is the tag used to specify where the actual provisioned hardware is, while in Azure, the equivalent tag is called location. There were many minor differences, so I refactored the code to make it more modular. Azure tag retrieval and AWS tag retrieval implementations had dedicated modules. In contrast, a shared module exploited them to support all hosts. This implementation abstracted the differences in cloud providers in the dedicated modules while keeping common functionalities such as caching tags in the shared module. This configuration also eases development for supporting more cloud providers in the future. After implementing Azure registration, we had an Azure bug hunt (a meeting to test some new functionality and find possible bugs). The first Shoreline bug hunt involved managing a multi-cloud environment.

A Shoreline cluster with multi-provider monitoring
After registration, I worked on deregistration: the process of removing a host once it is stopped or terminated. This entailed some challenges that were not present with deregistration for AWS. For example, there's no Azure SDK for Elixir, which meant that to get the hosts to deregister, we had to use the Azure SDK for Go in the scraper service. Through this process, I learned how to use a gRPC API and protocol buffers for communication across microservices. In addition to the actual implementation, we also had to maintain backward compatibility so that no older agents were attempting to execute a deprecated function.
Experience/Culture
At other companies, training and onboarding may take up much of a new hire's time, and it may be months before they can change code on an existing product. However, at Shoreline, I contributed to the codebase in just my second week of work. Working at Shoreline was something I looked forward to every day because of the interesting work and the people I got to work and interact with.
As an intern, I had one-on-one chats with various high-ranking members of the company, where I got to know a little bit more about Shoreline and ask any questions I had throughout my internship. I not only learned more about work and life at Shoreline, but I also had the chance to ask questions about advice on school and a career in the industry, as everyone I had talked to had a diverse career background. Getting to pick the brains of these Shoreliners for tips and advice through these one-on-ones was very helpful and informative.
In addition, the weekly new-hire/intern lunches and group lunches were something I always looked forward to, as it was fun to chat and get to know all of the Shoreliners. As a new intern joining an already existing team, I felt welcomed and never overwhelmed as everyone made it clear they were always willing to help if I needed it.
This help extended to the technical side of work as well. Every intern is assigned to a team related to their main project and is paired with a mentor, providing a reliable and robust support system of Shoreliners always willing to help if I got stuck somewhere. Coming into the internship, I had no experience related to cloud computing or distributed systems. Still, throughout the internship, I ended up learning so much with the help of my mentor and team: multiple languages, cloud providers, Kubernetes, CI/CD, microservices, and more.