

CoreDNS has been packaged with Kubernetes since v1.0.1 and has replaced both SkyDNS and KubeDNS as the default DNS server for Kubernetes. As a result, CoreDNS is at the core of Kubernetes service discovery. Without CoreDNS, pods cannot find one another, and communication between them breaks down -- if CoreDNS goes down, your entire cluster goes down with it.
Experienced operators running Kubernetes at scale will acknowledge that networking is complex with K8s, and often the most common problems and outages in a Kubernetes cluster come from DNS issues. Below are just a few of the many potential DNS problems within Kubernetes.
- In some scenarios,
systemd-resolved
resolv.conf - Iterating up to five search domains with the
ndots: 5 - Using
autopath - Under high load, some requests (especially TCP) are blackholed, even graceful termination setting the
weight: 0
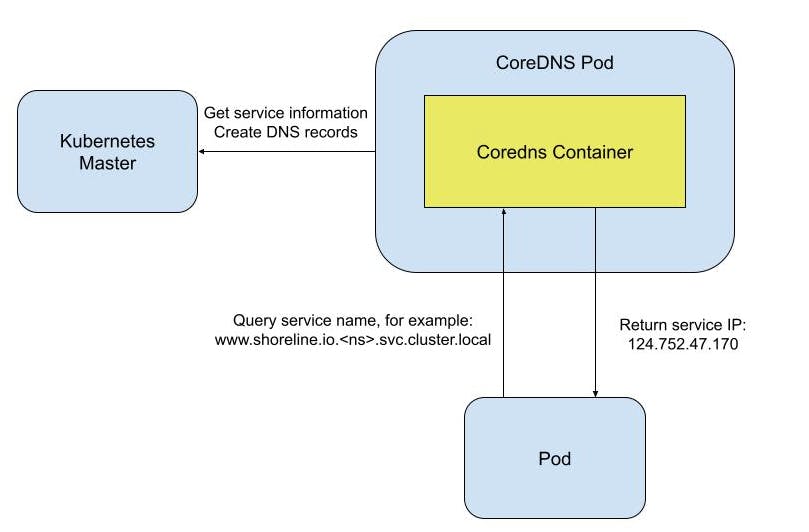
Given that CoreDNS is prone to issues, it is crucial that we carefully monitor the DNS before outages occur. Imagine a scenario where your frontend application goes down, and after investigation, you find that it is not resolving the backend endpoint because DNS keeps returning the dreaded 500 error.
Luckily CoreDNS exposes a rich set of metrics available to Prometheus. Retrieve metrics by accessing the endpoint with the following command: ``` curl localhost:9153/metrics
Many of these metrics monitor CoreDNS for latency. Unfortunately, too many calls to the DNS service may cause massive latency. Once latency between the pod and CoreDNS reaches one second or more, it impacts both the customer and ultimately their SLA. However, most organizations merely monitor CoreDNS and continue to manually address the issue, causing unacceptable delays and potentially system outages.
## Shoreline CoreDNS Op Pack
Shoreline Op Packs consist of a pre-packaged set of [*Alarms*](https://docs.shoreline.io/alarms), [*Actions*](https://docs.shoreline.io/actions), and [*Bots*](https://docs.shoreline.io/bots) delivered as Terraform modules, which are easy to configure and fast to deploy.
The Shoreline CoreDNS Op Pack monitors metrics and automatically triggers an [*Action*](https://docs.shoreline.io/actions) that restarts the CoreDNS pod once latency exceeds a configurable threshold. In addition, the Op Pack includes a configuration map for ingesting metrics from the CoreDNS Prometheus exporter so you can immediately leverage them. For details on modifying the configuration map, check out the [*Metric Scraper: resource\_mapping\_config*](https://docs.shoreline.io/installation/kubernetes/metric-scraper#resource_mapping_config) documentation.
Below are some of the key features and benefits of the CoreDNS Op Pack:
- Shoreline gathers CoreDNS metrics as frequently as once per second, so we can use multiple data points and different percentiles when deciding if CoreDNS resolves slowly or not.
- Shoreline focuses on DNS latency rather than overall measured latency because it helps disambiguate latency from the network versus latency from DNS resolution. This practice prevents false positives when the clusters experience high network latency. The [*Alarm*](https://docs.shoreline.io/alarms) threshold is configured in milliseconds so that you can tightly control the latency tolerance.
- Shoreline uses rolling restarts of the CoreDNS pods to prevent service outages. Kubernetes version 1.15 and above supports rolling restarts:
kubectl rollout restart -n kube-system deployment/coredns ```
- Optionally the CoreDNS Op Pack can automatically create a PagerDuty incident or Slack message when an Alarm or Action is triggered. The notification includes the affected Resource, latency measurement, and any executed Action (e.g., restarting the CoreDNS pod). This capability eliminates another manual step by automating the notification process for further root cause analysis.
Conclusion
Please click here for a demo of Shoreline’s CoreDNS Op Pack or incident automation in general. We would love to schedule a demo session and discuss how Shoreline can help your organization reduce operator toil.