

1. A Detailed Postmortem of Square’s August 2023 Outage
“Shares closed 5% lower as a result of the outage which is over a billion dollars in market cap evaporated.” (Watch Video)
Learning from the incidents that other companies encounter is an essential part of handling and recovering from similar challenges. In this video, Anurag goes into detail on what was known, and what could be derived, about Square’s 36-hour outage, costing over a billion dollars in market cap for its parent company, Block, Inc.
💡Key Insight: When it comes to resiliency, we all need to design systems with failures in mind, not the 'happy path.'
🔗 Learn More: See how Razorpay automated its incident management, resulting in a 20% reduced “Time to Isolate.”
2. Three Lessons from Building $1B Services
“At AWS, I had the unusual opportunity to create around half a dozen services that crossed a billion dollars each in revenue.” (Watch Video)
After building half a dozen services at AWS that crossed a billion dollars in revenue, Anurag Gupta shares a few simple lessons for those looking to follow in his footsteps:
- Pick the right market, and know the Total Addressable Market size (TAM)
- Hire the right people, and make sure that they have the drive to innovate and do things differently - this is more important than domain knowledge
- Make products that are easy to buy - where customers are already looking for a solution and can try out the experience.
💡 Key Insight: Go after markets that are large, where people already know they want something, and make it easy for them to try out your experience with low commitment.
🔗 Learn More: AWS is famous for its approach to opening meetings with a collective reading of a narrative. Anurag explains how to write one here.
3. The Wrong Way to Use Runbooks for DevOps and Cloud Operations
“I've even seen a runbook saying, ‘page Dave.’ That was all. By the way, Dave doesn't even work there anymore.” (Watch Video)
Runbooks should provide on-call engineers with the gold standard in incident resolution, but Anurag has seen more than a few questionable practices. Imagine you’re on call and need to choose between one of three runbooks poorly maintained as: 1) Rebalancing Kafka , 2) Rebalancing Kafka - New version, and; 3) Rebalancing Kafka - John's recommendations.
The reason this happens is actually simple – traditional Runbooks aren't runnable, so there's no motivation to keep them up to date. Leading DevOps and Cloud Operations teams are looking to incident management tools like Shoreline that offer executable runbooks to help create self-healing infrastructure.
💡 Key Insight: Runbooks offer a ‘collective memory’ for your L1 team on call and can help them avoid mistakes and escalations to your dev team (as long as they are up-to-date).
🔗 Learn More: Build your own runbook in seconds with Shoreline.io’s free GenAI tool.
4. Don’t Skip Weekly Operational Reviews
“I've seen people go and focus on innovation, innovation, innovation, collect a bunch of tech debt, and then suddenly turn out to have a whole cascade of issues that were just sitting there.” (Watch Video)
Sole emphasis on innovation can end up with a situation like “camping in a minefield” says Anurag in this video on the importance of dedicating resources to operational excellence. He reminds us that process, like a weekly operational review, can be as essential to reliable systems as tools.
And tools like Shoreline can help make collecting the data for weekly operational reviews less laborious and bubble up the best opportunities for improvement. Continuous improvement is about getting 1% better every week.
💡Key Insight: Build a continuous improvement process and allocate a portion of your team's time to reliability, just as you do for defects.
🔗 Learn More: See how your peers are operationalizing incident management in our in our 2023 Benchmark Report.
5. Become an On-Call Expert with AI-Powered Runbooks for DevOps and Cloud Operations
“That's really our goal here, to make engineers' lives stress-free. That's why it's called Shoreline.” (Watch Video)
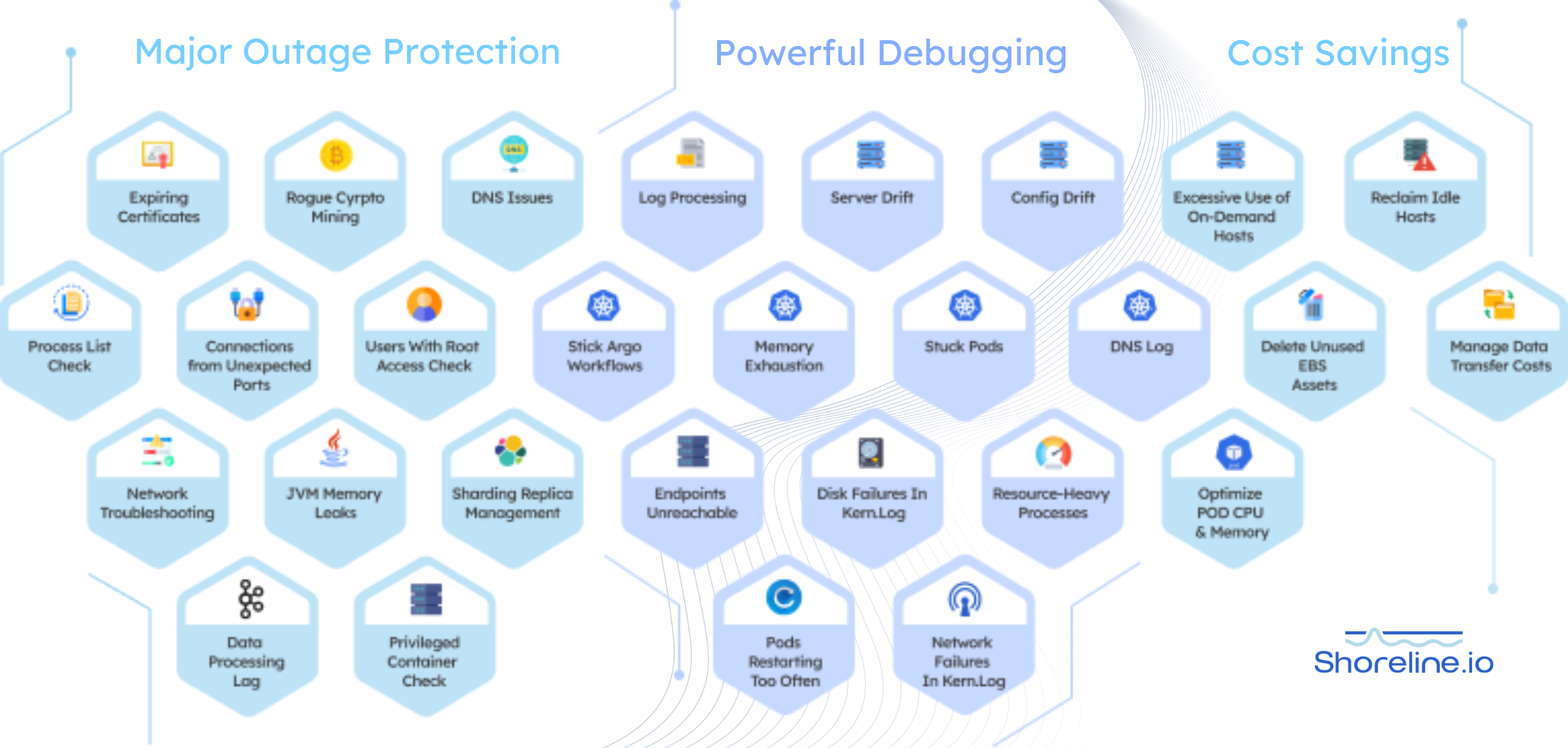
As Anurag says in the beginning of this video, being on call is like becoming “an expert on everything that might go wrong, which is impossible”. DevOps excellence isn’t about knowing all of the answers. It’s about having the right tools, like a structured and correct runbook at the moment it is needed. This is why Shoreline created the Runbook Library with 500 pre-built and validated runbooks for common issues like Major Outage Protection, Debugging, Cost Savings, Kubernetes issues and more.
💡 Key Insight: DevOps and Cloud Operations teams face immense on-call pressure and increasingly complex environments. Since you can’t know everything, runbooks are the launching point for structure and correct actions.
🔗 Learn More: Check out Shoreline’s 500 pre-built and validated runbooks to help quickly fix your most common problems.
These top five videos of 2023 offer valuable insights into best practices in DevOps and Cloud Operations. From dissecting major outages to leveraging AI for on-call management, Anurag provides a roadmap for teams to excel in this evolving field.
Want to hear more from Anurag? Follow him on LinkedIn and join him at the reliability.org slack channel .
Check out the Shoreline.io You Tube Channel for more executive insights.