
How it Works
Shoreline for GPUs activates, debugs, and remediates GPUs across public clouds, private clouds, and virtual and physical hardware. Learn more
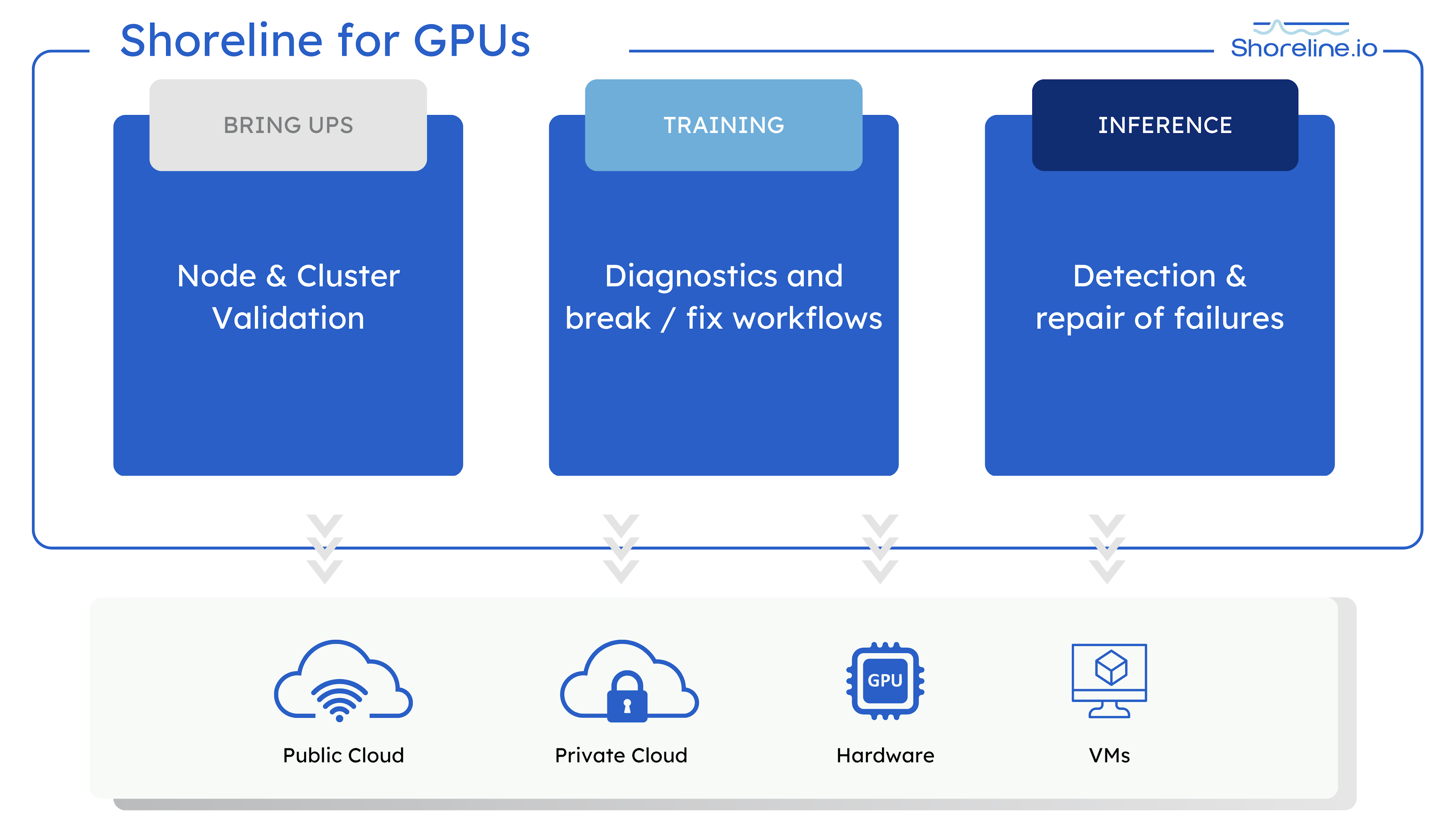
- Accelerate day 1Speed up capacity verification for new GPUs
- Bring up each GPU quickly with minimal manual effort using automations that perform single-node validation, diagnostics, point-to-point verification, and performance and stress tests.
- Proactive day 2 repairsRepair faster with automated break/fix workflows
- Avoid lengthy debugging cycles and outages with automated break/fix workflows. Use remediation actions including cordoning, draining, and restarting impaired nodes to keep GPUs running.
- Reduce GPU expenses with monitoring and issue detection
- Ensure all of your expensive GPU resources are operating at peak capacity with system-wide monitoring for availability, degradation, or breakage.
- Drive up throughput for training workloads
- Ensure every node is at full operational capability during training workloads that require significant resources. Rightsize GPU jobs, detect laggard nodes, and automate diagnosis & repair.
- Drive down latency for inference workloads
- Reduce slow-downs and non-responses during inference workloads by right sizing, scaling, scheduling and sharing resources with Shoreline tooling.
Shoreline for GPUs
Maximum GPU Utilization
Shoreline.io connects to your GPU infrastructure and control plane as a single access point and real-time view of production systems. Permissioned users have performance visibility, cost analysis, single-touch hardware bring ups and no-code remediations with secure, audited access.
- GPU monitoring & observability
- — Each node needs to operate at peak performance for training and lighting-fast inference. Shoreline monitors across Kubernetes, bare metal and Slurm AI clusters whether on prem or in any cloud, allowing you to quickly pinpoint GPU breakage or degradation.
- GPU cost management
- — Shoreline reduces operational costs and creates a more sustainable fleet. Our solution offers rapid bring-ups, prewarming strategies and sleep modes for enhanced resource efficiency and flexible capacity adjustments with scaling inference capacity to align with demand fluctuations.
- GPU resource fleet management
- — Shoreline scales seamlessly from a few nodes to thousands, ensuring consistent performance regardless of your infrastructure's size. With real-time distributed execution and a GitOps-managed runbook library, our solution optimizes operational efficiency and simplifies the management of complex systems, making it the ideal choice for businesses aiming for high scalability and reliability.
- Production access control
- — With Shoreline, your GPU infrastructure becomes a secure and auditable environment, with role-based access control to only specific actions without needing to provide SSH or sudo to your operators. All access is secure and audited.