

This is our first post in a series to demystify the metrics engine that underpins Shoreline’s real-time data. Each of these posts will be a deep dive into one aspect of the engine and how it benefits SREs/DevOps/Sysadmin while they're on call. We’ll showcase our most interesting applications in machine learning, compression, compilers, and distributed systems.
During an operational event, as an SRE, I run ad hoc queries to debug the system. I want these to be real-time no matter how complex the computation or volume of data. Shoreline’s metrics team has leveraged two machine learning technologies from Google, JAX and XLA, to accelerate metric query and data analysis. Within Shoreline, queries are automatically vectorized using JAX and compiled using XLA, offering optimal performance without any extra user work. This allows Shoreline to compute complex, ad hoc aggregates across 100,000s of data points in a few milliseconds.
While metrics help SREs understand the health of their infrastructure and applications, crafting a metric query can be a complex task involving derivatives and vectorized mathematics. For example, using Kubernetes’ node exporter to compute CPU usage for a host involves a derivative, an average, and other vector arithmetic. JAX is a Python frontend to XLA and XLA is the linear algebra compiler backing TensorFlow, Google’s famous machine learning framework. Within Shoreline, we map metric queries to tensor operations and compile them, leveraging the same stack that is used in these contemporary machine learning systems.
In this post, we’ll dive into how we’ve incorporated JAX & XLA into Shoreline.
How do we execute a metric query?
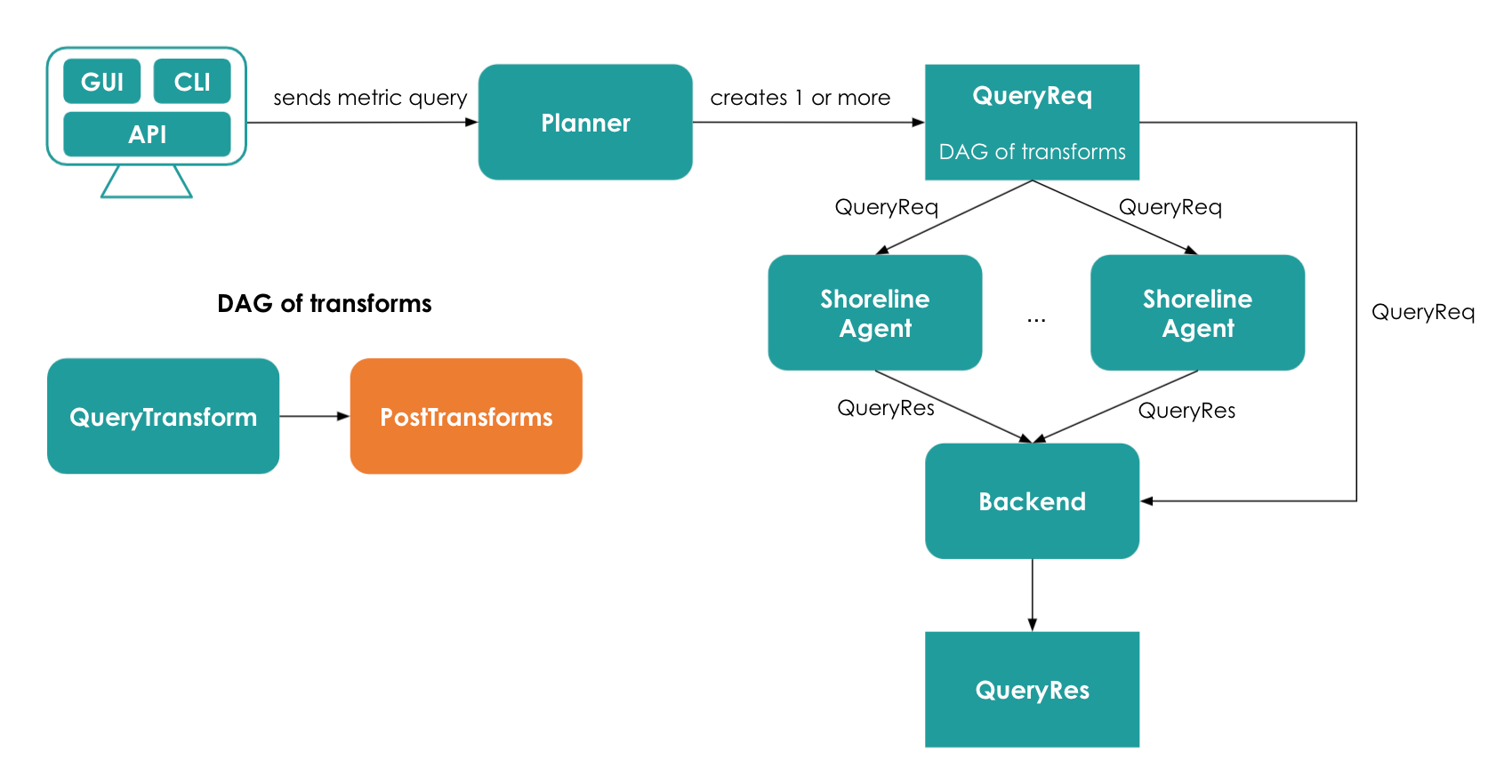
When you write a metric query (a statement written in Shoreline’s Op language) through Shoreline’s UI, CLI, or API, it gets sent to what's known as a planner. The planner parses the query and builds a plan - the distributed set of steps needed to fulfill the query. A plan is a directed acyclic graph (DAG) of steps.
Data can reside within Shoreline’s backend or on an agent. Every agent in Shoreline continuously collects real-time metrics about everything happening on its host. Periodically, the agents send data to the backend for permanent storage. In order to support truly real-time metric queries, the planner takes into account if the data is available on the backend or the agents. When a query demands the most timely data, the planner transparently fans out the query, contacting the agents and the backend systems.
After data access, the planner also needs to determine how to compute the derived values on top of this raw data. Originally, this was done using an interpreted system, which provided for high flexibility at the expense of execution speed. It’s this component that Shoreline has significantly enhanced with JAX and XLA.
Using JAX & XLA
Let's take a step back and think a bit about the data we are collecting. Each metrics agent is collecting data at the same time, albeit on different machines. Most time-series databases, therefore, think of their data as a sort of dictionary, where the key is a timestamp, and the value is the metric we're tracking. We take a different approach. Shoreline samples every second, yielding dense data. Shoreline has a time alignment algorithm that normalizes timestamps.

The result is a matrix - the standard representation of data for machine learning. This allows us to leverage the recent advancements in tensor computation.
For each operation on metrics, we mapped the operation to matrix mathematics supported by JAX. We like to think of every metric query as a graph of matrix operations. For example, looking back to our CPU usage metric query from node exporter, the derivative of the counter becomes a convolution, the average across the CPUs becomes a matrix operation, and the arithmetic operations becomes vector arithmetic on the tensors.
After this graph is built, XLA is invoked to compile metric queries to machine code. This machine code efficiently executes, generating the final result for the user. JIT compilation allows the entire build process to happen in hundreds of milliseconds, allowing for acceleration of entirely ad hoc queries.
Optimizing the DAG

Structurally, this compilation is implemented similarly to other optimizing compilers. First, the planner outputs an initial plan that has no compiled steps. An optimizer then considers the plan, looking for opportunities to replace computation with operations for XLA. After identifying subgraphs that can be compiled, the optimizer looks into its cache to see if it has already generated code for these optimizations. If it has, the optimized plan is returned, otherwise, compilation is run. This optimization is entirely transparent to users of Shoreline: all of this happens automatically whenever Op is executed without any adjustment needed.
Not every step inside of a metric query plan can be compiled. For example, the plan will have data access operations i.e. reading data from disk or in-memory cache or steps for generating an output in the appropriate format. The handling of missing data and data sampled at different resolutions also must be handled to ensure the matrix mathematics functions correctly.
Looking to the Future
So far the results are very encouraging. Processing ~100,000 data points through a sequence of simple vector operations takes single-digit milliseconds. More complex operations can take longer, but we are tracking towards our goal of every metric query taking less than one second.
We are constantly trying to improve the performance of our query and data analysis systems. In follow-on posts, we’ll describe how we accelerate the computation of alarms by shipping compiled queries from backend to agent. We’ll also cover how we leverage all of this infrastructure for analytical applications.
As always, if any of this work interests you—we're hiring!